Our main research lines are:
Reduction processes represent one of the most common and useful chemical transformations carried out in industrial and fine chemistry. In our group, we have already developed new homogeneous catalysts for the reduction of carbonyl compounds into alcohols via hydrosilylation. These new catalysts suppose a step forward towards the sustainability of chemical processes, as they are based on Earth-abundant metals, such as iron and lithium, instead of the expensive noble metals (rhodium, ruthenium, iridium, platinum, etc.) that have constituted the basis of many homogeneous catalysts so far. Furthermore, these new first row-transition metal complexes have demonstrated to be near as efficient as the traditional ones, based on second- and third-row transition metals, working at room temperature and low catalyst loadings (< 1 mol%). Such efficiency has been reached thanks to ligand design.
The chemical and electronic properties (hemilability, non-innocence, chelation, coordination geometry, etc.) of the ligands in a coordination compound may affect dramatically the properties of the metal center, tuning its reactivity or selectivity. Though the ability of iron- and lithium-based complexes to reduce ketones and aldehydes via hydrosilylation have been proved, the reduction of other substrates, including alkenes, esters, nitrogenated functions and CO2, will be explored as well, for what new homogeneous catalysts will be further developed. These complexes based on cost-effective and environmentally benign metals will be also employed as catalysts for the synthesis of polymers, particularly polyethylene. The properties of the resulting polymer should be tunable by changing reaction conditions (temperature and ethylene pressure), the presence of co-monomers and the nature of the catalyst. The synthesis of biopolymers, such as polylactic acid, have also received great attention in industrial setting, as they are biodegradable and thus environmentally-friendly. Therefore, the employment of biopolymerization catalysts that do not rely on contaminant metals is highly desirable, which motivates us to study the implementation of our "green" catalysts and organocatalysts for the polymerization of lactic acid as well. In order to improve all these catalytic processes to the point that they are applicable in industry, a convenient understanding of the reactions must be reached. To this end, all new catalysts will be characterized in solution and solid state, via multiple analytical and elucidation methods, and the catalytic processes will be modeled by computational calculations along with experimental mechanistic studies.
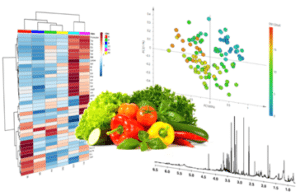
Metabolomics is a promising tool to study the complete set of naturally present or stresses-elicited metabolites of a biological system and generates novel information on its metabolic networks and their regulatory steps. The qualitative and quantitative determination of the cellular metabolites offers a unique opportunity to explore the biochemical mechanisms involved in cellular functioning, in order to relate them to the observed phenotype. This tool takes advantage of advanced analytical platforms, such as Nuclear Magnetic Resonance (NMR) or Mass Spectrometry. Broader use of metabolomics in agri-food sector is providing in-depth knowledge on fruit composition and nutritional value, which is helpful to improve fruit quality through plant breeding and cultural practices.
Metabolomics can generate comprehensive data on metabolic networks (primary and secondary pathways of sugars, organic acids, phenolic compounds, ethylene synthesis, etc.), which is crucial in setting the appropriate cultivation/postharvest treatments, and to divert the metabolism towards the desired pathways, or slowing down the undesired pathways. Enhancing fruit quality, particularly nutrients that potentially benefit human and animal health, and flavor/aroma components, has generated considerable research interest among nutraceutical and horticultural industries. This research group is involved in several national and international projects and research contracts based on the application of NMR metabolomics coupled to various statistical analysis techniques to the agri-food sector, to study several fruits and vegetables such as tomato, zucchini, melon, cucumber, pepper, etc. For example, in the case of tomato, we have been focusing on the understanding the effects of the addition of biopesticides to crops and how they influence their metabolome.
Metabolomics has also vast application on other sectors, such as on pharmaceutical and clinical fields. It allows to monitor disease development, identify in vivo mechanisms of action for novel drugs, and evaluate mechanisms of drug resistance. This group is also involved in two projects related to clinical setting. The first involves the analysis of embryo culture media to predict embryo quality and, hopefully, increase the success of IVF technique. The second aims to understand the effect of prenatal and postnatal exposure to the organophosphate Cpf that will induce different neurobiological, inflammatory and behavioral changes (social behavior, learning and memory, GABAergic system maturation, ion chloride concentration, reelin expression, microbiota variability and metabolomics) in mice as a function of age and sex.
Studying solution molecular diffusion give us information about a wide range of physical molecular properties including molecular size, shape, aggregation, encapsulation, complexation and hydrogen bonding. This NMR measurements can be applied to complex mixtures in order to unravel the number of components, the signals associated to each species, the molecular weight of each component, and in the case of polymers, knowing for instance the polydispersity index. In order to approach to all these problems, it is necessary to apply a regression fitting. The observable variable is the diffusion coefficient, which is estimated from experimental data, through the theoretical inversion of Laplace Transform (ILT). The research group have developed several mathematical approaches to solve the ILT via genetic algorithms or algebraic reconstruction techniques. With these tools on hand together with already published strategies such as TRAIn, ITAMeD, CONTIN, NNLS, etc. we are predicting average-weight molecular weight in polymer blends and establishing their polydispersity indexes, and currently, on how we could measure these type of experiments without spectrometer calibration, that is, with no dependence on the molecular size of the components in the specific mixture.